

Authors: Yannik Müller, Ilya Zhukov and Vitor Silva (Jülich Supercomputing Centre, Forschungszentrum Jülich, Jülich, Germany)
I. Introduction
Efficient communication among processes is vital in the High-Performance Computing (HPC) world. To gain insights into the current network’s state and identify potential bottlenecks, a reliable network benchmarking tool is required. This is where LinkTest comes in – a robust communications benchmarking tool designed to test point-to-point connections between processes in serial or parallel mode, and capable of handling very large numbers of processes (tested up to 1 800 000 MPI tasks). It can communicate via MPI[1] or lower-level protocols such as UCP[2], IB Verbs[3], PSM2[4] and NVLink[5] bridges via CUDA. The output of the program consists of a binary file (SIONlib)[6] containing a complete communication matrix of message transmission times for all process pairs, and a standard log file summarising the results. Tools are provided to read the generated SION file into Python and to generate PDF reports and graphs out of the collected data. In the RED-SEA project, LinkTest received more direct support for BXI (The BullSequana eXascale Interconnect) through the utilization of Portals, a low-level network API. A BXI through Portals driver is part of the BXI software stack in RED-SEA.
In the first phase of RED-SEA project, LinkTest was used to compare the two test platforms: DEEP (portion with BXI network) and Dibona along with two MPI implementations: OpenMPI and ParaStationMPI. The obtained results were then compared with the tests executed on the Infiniband portion of the DEEP system. In the second phase, LinkTest was extended with direct Portals support and the studies were continued with updated versions of the BXI software stack. Some of the preliminary results of those studies will be presented as well as some details about decisions taken while implementing the Portals support in LinkTest.
II. What exactly does LinkTest do?
LinkTest measures the bandwidth and/or latency of messages between two processes. It has two modes, i.e. a serial and a parallel one. In serial mode, only one pair of processes communicate at a time thus the measured bandwidth should be close to the theoretical maximum bandwidth. In parallel mode, where N processes are involved in the entire LinkTest run, N/2 pairs communicate at the same time, thus creating maximum stress on the connections between processes. The communication occurs in a specified pattern known as ”kernel”. After each step, the pairings of processes change, ensuring that all processes eventually have the opportunity to communicate with each other. It is necessary to note that the parallel bandwidth does not only depend on the pair of communicating processes but also all other pairings. A communication pattern is a partition of all N processes into N/2 unordered pairs. In theory, each communication pattern could yield a different parallel bandwidth. In practice interconnect topologies often have symmetries, leading to similar results for many communication patterns. The number of possible communication patterns is ![]() which is too big to test them all. LinkTest calculates (N-1) communication patterns with the 1-factor algorithm. This algorithm ensures that each process will be paired with any of the other processes exactly once and while using the minimum required steps (N-1) to do so. One may choose to re-run LinkTest multiple times with the –num-randomize-tasks option. This option randomly shuffles the task numbers given to the 1-factor algorithm, thus a different subset of communication patterns will be generated each time.
which is too big to test them all. LinkTest calculates (N-1) communication patterns with the 1-factor algorithm. This algorithm ensures that each process will be paired with any of the other processes exactly once and while using the minimum required steps (N-1) to do so. One may choose to re-run LinkTest multiple times with the –num-randomize-tasks option. This option randomly shuffles the task numbers given to the 1-factor algorithm, thus a different subset of communication patterns will be generated each time.
A. LinkTest Kernels
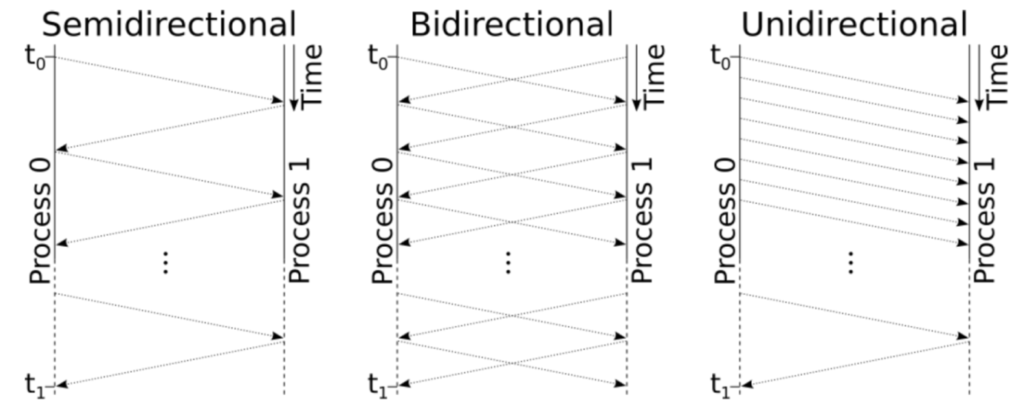
LinkTest supports three different Kernels, i.e. semi-directional, bidirectional and unidirectional (see Figure 1). These three kernels test slightly different things. The semi-directional case corresponds to the default ping-pong test, in which a message is bounced a given number of times between two processes. In the bidirectional case, two messages are bounced between the two processes in parallel. In the unidirectional case, the first process repeatedly sends the message to its partner. Once the partner received all messages, it sends a single message back.
For RED-SEA these kernels need to be implemented with the Portals API. The (non-)blocking behaviour of the API needs to be taken into consideration in order to create comparable kernels throughout all the supported APIs. For MPI and most other APIs, the send and receive buffers do not need to be prepared. They are given directly to the send/recv calls. For Portals however both need to be registered in a memory descriptor (sender) and list entry (receiver). This is happening before the kernel starts measuring time.
B. Send/Recv vs Put/Get
One of the fundamental differences between MPI and Portals communication is that MPI is based on send/recv operations whereas Portals uses put operations. The put operation and, in general, the Portals API are on a lower level compared to MPI. MPI can be implemented on top of Portals, as shown in the following blog post[7], or the user may choose to use asynchronous communication instead.
The sender initiates a put operation by sending a put request containing the data to the target. The target does not need to post a corresponding ”receive” operation, instead it uses the already registered buffer for receiving the data. The writing into the buffer will happen asynchronously during the program execution. That approach is more time-efficient than an irecv operation, for example. Unexpected messages without a predefined receive buffer are stored in a separate space. Later the receiver could still check for such unexpected messages.
C. Acknowledgements
Portals offers acknowledgements for put operations. However, for the sake of comparison we have decided to send explicit acknowledgements instead. This way it is possible to get finer-grained control over the amount of messages being sent. The semi and bidirectional kernels have implicit acknowledgements since the time-measuring process is the one that receives the last message. For the unidirectional kernel the acknowledgement is explicitly the last message itself.
III. STUDY
The most recent study consists of serial LinkTest runs with message sizes from 1KiB to 16MiB, in MPI mode and Portals mode, on DEEP (dp-bxi) and Dibona (production).
A. DEEP
Additionally we included one series with MPI on DEEP (dp-cn) with an Infiniband Interconnect. At the time of the study there was no OpenMPI available in the DEEP system, so all tests on DEEP were done with ParaStationMPI.
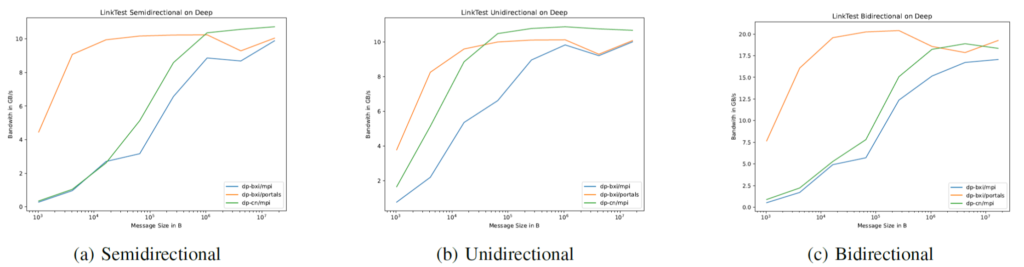
In orange we see the Portals implementation running on the BXI nodes. In blue the MPI implementation on the same nodes. For small message sizes, the put-based kernels are much faster than the MPI implementation. The theoretical maximum bandwidth (11,64153 GiB/s) is already approached with 16KiB messages.[8] For larger message sizes the MPI implementation on the BXI nodes approaches exactly the same bandwidth as the Portals implementation. For smaller message sizes latency is the bottleneck limiting the bandwidth. The latency is not only the travel time through cables, switches and NICs but also the software latency. Here Portals offers some optimization potential since buffers for sending and receiving can be prepared before the kernel even starts. It raises the question whether the MPI kernel could be improved by using MPI_Put instead of MPI_Isend. However, for other types of hardware that might also have the opposite effect.
The unidirectional kernel allows it to hide a lot of the latency and achieves higher bandwidths earlier. The bidirectional kernel shows bandwidth twice as high as the semidirectional kernel for medium and large messages and a little bit less than twice for small messages. This is exactly the expectation for truly bidirectional connections. The runs on BXI nodes show a dip in performance for 64KiB messages compared to 16KiB.
The green line shows the MPI implementation running on the DEEP with an Infiniband Interconnect (cluster nodes). The performance dip at 64KiB is not present here indicating that the reasons are BXI (hardware or driver) related. Other than that it behaves similarly to the MPI over BXI run but with better performance throughout. The maximum reached bandwidth is 10% higher. Since the hardware of the nodes (and, of course, the interconnect) differs it is not immediately clear how comparable these runs are.
B. Dibona
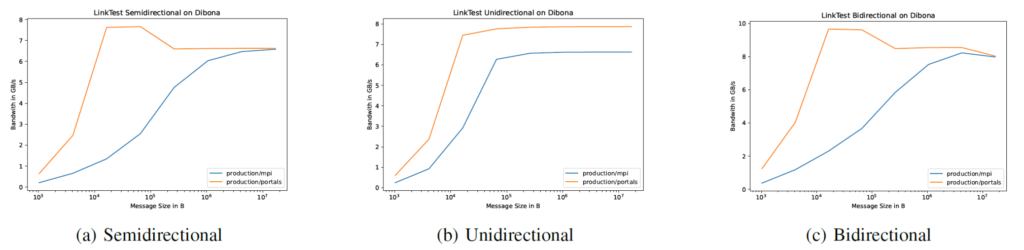
On Dibona, we observe a slightly different scenario. The Portals implementation is again depicted in orange, while the MPI implementation is shown in blue. Notably, for small message sizes, the Portals implementation outperforms the MPI one significantly as it did on the DEEP system. Weirdly the portals version reaches its maximum bandwidth for medium message size and then drops off for larger ones. Additionally, the bidirectional kernel demonstrates only slightly better bandwidth compared to the semidirectional kernel. Probably there is some misconfiguration preventing the achievement of larger bandwidth. Since the DEEP runs have shown that the BXI interconnect is definitely capable of truly bidirectional communication. The unidirectional kernel proves highly effective in reducing latency, thus the mpi version exhibits notably faster performance for small and medium messages. But also it shows approximately 20% higher bandwidths for large messages. Interestingly the portals version maintains a constant lead even for larger message sizes.
In summary, the Dibona results are a bit more surprising. They are far off the maximum theoretical bandwidth and there are multiple anomalies. In contrast to the BXI nodes on deep, the Dibona system was used by other users at the time of testing. The measurements might turn out differently when the system is otherwise empty.
IV. Conclusion
In RED-SEA LinkTest has been extended with direct Portals support and tested on both test platforms in multiple configurations. The implementation process highlights the details of communication protocols and how they influence performance. The Portals API allows for some latency optimizations compared to MPI that are visible in all three kernels. The MPI kernel implementation could possibly be optimized on this type of hardware to match the performance of portals.
References
[1] K. Raffenetti, A. J. Pena, and P. Balaji, “Toward implementing robust support for portals 4 networks in MPICH,” in 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, pp. 1173–1176, 2015.
[2] P. Shamis, M. G. Venkata, M. G. Lopez, M. B. Baker, O. Hernandez, Y. Itigin, M. Dubman, G. Shainer, R. L. Graham, L. Liss, Y. Shahar, S. Potluri, D. Rossetti, D. Becker, D. Poole, C. Lamb, S. Kumar, C. Stunkel, G. Bosilca, and A. Bouteiller, “Ucx: An open source framework for hpc network apis and beyond,” in 2015 IEEE 23rd Annual Symposium on High-Performance Interconnects, pp. 40–43, 2015.
[3] Mellanox Technologies Inc., Mellanox IB-Verbs API (VAPI), 2001.
[4] Intel, Intel Performance Scaled Messaging 2 (PSM2) Programmer’s Guide, November 2015.
[5] NVIDIA, “NVLink and NVSwitch.” https://www.nvidia.com/en-us/data-center/nvlink/. [Accessed 27-07-2023].
[6] W. Frings, F. Wolf, and V. Petkov, “Scalable massively parallel i/o to task-local files,” in Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, SC ’09, (New York, NY, USA), Association for Computing Machinery, 2009.
[7] “Extending parastation mpi by bxi support.” https://redsea-project.eu/extending-parastation-mpi-by-bxi-support/. [Accessed 27-07-2023].
[8] Atos, “High performance interconnect for extreme hpc workloads,” tech. rep., Atos, 2019.