

Authors: Simon Pickartz (ParTec), Carsten Clauss (ParTec)
The ParaStation MPI communication stack is a central pillar of ParaStation Modulo. This is a comprehensive software suite especially designed for systems following the design principles of the Modular Supercomputing Architecture (MSA). It is the selected middleware powering the DEEP projects but is also extensively used in production environments, e.g., on the JUWELS Cluster/Booster system at Jülich Supercomputing Centre (JSC) [1] and the modular MeluXina system in Luxembourg.
In the context of the RED-SEA project, ParaStation MPI has been extended by support for the BXI interconnect. This work does not only enable efficient communication in such networks when using ParaStation MPI, but also enables seamless MPI communication in heterogeneous MSA systems containing BXI modules. This blog article focuses on the implementation of the BXI support in ParaStation MPI and provides insights to its architectural design while showing early performance figures obtained on different hardware testbeds.
An Introduction to ParaStation MPI
ParaStation MPI is an MPICH [2] derivate relying on the pscom library [3] for point-to-point communication. It is used to implement the PSP device (cf. Fig. 1) which, in turn, implements the ADI3 interface. ADI3 separates the hardware-independent communication facilities (e.g., datatype handling, collective communication, etc.) from the hardware-related counterpart (e.g., transport-specific Remote Memory Access (RMA) operations). Following this concept, the PSP device implements MSA awareness in ParaStation MPI, e.g., by providing multi-level, hierarchy-aware collectives taking the topology of MSA systems into account and by providing facilities for determining the module affiliation at the application level.
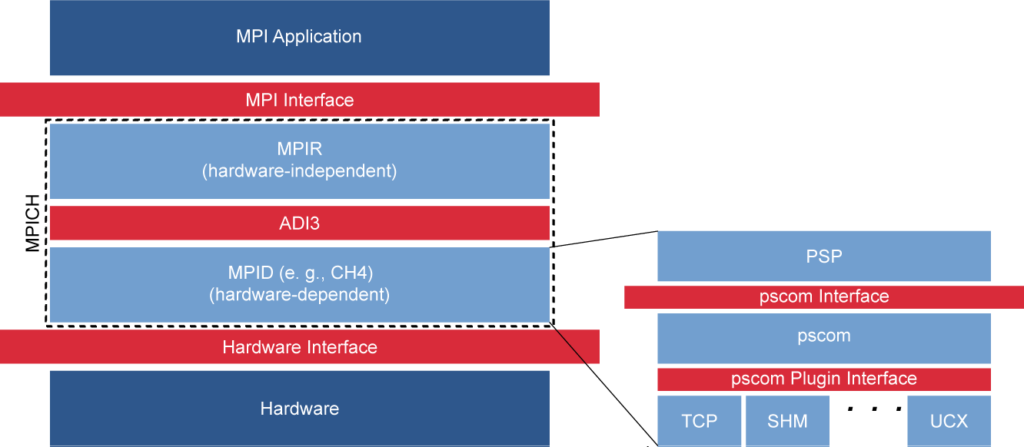
The pscom is a low-level communication library and is especially designed for HPC systems. It targets high-performance communication and ships with a variety of plugins supporting different interconnects and interfaces relevant to the HPC domain, e.g., InfiniBand (IB)[5], UCX, Extoll [6], and Omni-Path [7]. These transports and protocols can be used concurrently and transparently by the processes of a parallel application, i.e., processes automatically choose the transport promising the best performance depending on the their locality within the system.
The pscom itself is divided into different software layers (cf. right-hand side of Fig. 1): The hardware-independent layer facilitates the session management and defines bi-directional connections between different pscom processes. The hardware-dependent layer, in turn, features a modular design supporting different communication interfaces and protocols by means of plugins.
Design and Implementation of the pscom4portals Plugin
As outlined above, ParaStation abstracts from the hardware by relying on the facilities provided by the pscom and there, in turn, on the different plugins. Therefore, the natural way for adding support for BXI to the ParaStation MPI communication stack is to implement an appropriate plugin interfacing with the pscom.
This approach not only enables MPI communication over the BXI network but also allows applications to run on heterogeneous network landscapes supported by the gateway facility of pscom [8]. This aspect is likewise interesting in the context of the DEEP-SEA project as the work described here opens up the ability to use BXI-based computing modules within MSA systems.
Architecture
The pscom4portals plugin relies on the Portals 4 API [9] for interfacing with the BXI hardware. Similar to other pscom plugins, pscom4portals is logically divided into two layers (cf. right-hand side of Fig. 2): (1) the upper layer implementing the interface to the hardware-independent part of the pscom and the lower psptl layer implementing a point-to-point communication channel by leveraging the Portals 4 API.
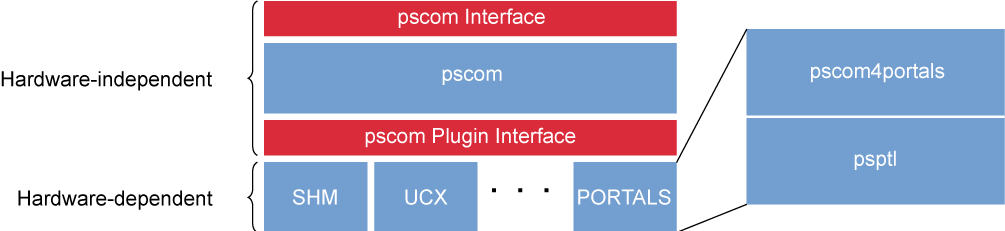
The main purpose of the upper layer is to implement the handshake mechanism of the pscom. This enables the processes to mutually agree on the communication transport to be used. Additionally, this the upper layer provides the necessary callbacks for sending and receiving data over pscom4portals connections.
Communication Protocols
Depending on the message size, the pscom4portals plugin uses either eager or rendezvous semantics.
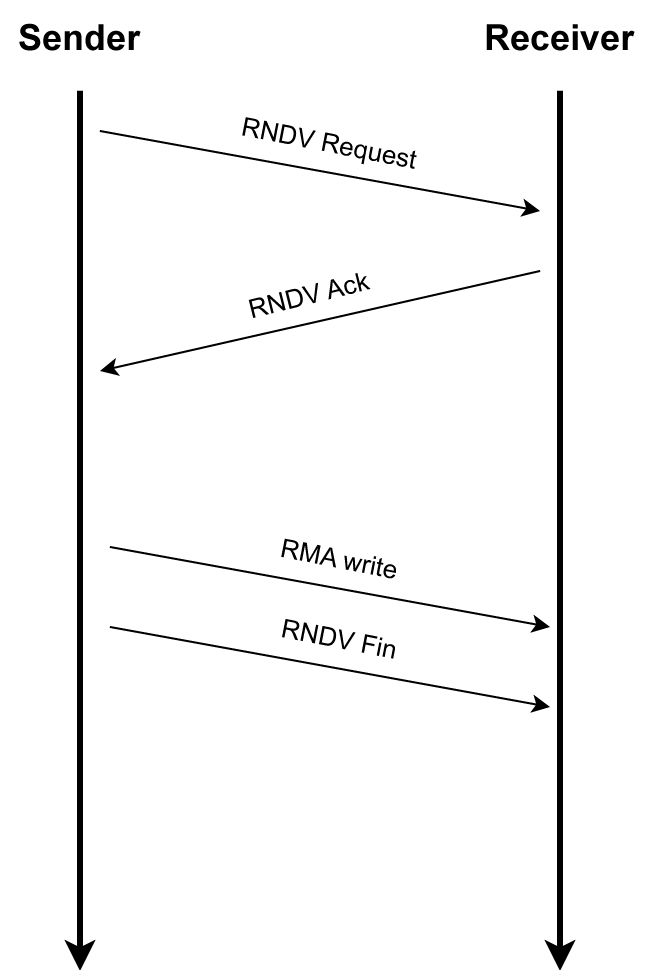
For the latter, it implements a Put-based protocol relying on RDMA write operations (cf. Fig 3). Both communication paths are separated by allocating dedicated Portal Table Entries (PTEs) each, i.e., each process initialising the pscom4portals plugin allocates two PTEs in total.
The pscom4portals plugin provides a set of environment variables for influencing its runtime behaviour. This enables fine-tuning of the communication performance, e.g., the threshold when to switch the protocols can be defined by setting the PSP_PORTALS_RENDEZVOUS environment variable (cf. Tab. 1).
| Variable | Description |
|---|---|
PSP_PORTALS_MAX_RNDV_REQS | Maximum number of outstanding rendezvous requests per communication pair |
PSP_PORTALS_RNDV_FRAGMENT_SIZE | Maximum size of the fragments being sent during communication |
PSP_PORTALS_RENDEZVOUS | The rendezvous threshold |
Eager Communication
The eager mode leverages pre-allocated send and receive buffers for the data transfers. These are created during the initialisation of a pscom4portals connection and exclusively used between a given pair of processes. Again, a fine-tuning of the runtime parameters is enabled by according environment variables, e.g., by setting number and size of these pre-allocated communication buffers (cf. Tab. 2).
| Variable | Description |
|---|---|
PSP_PORTALS_BUFFER_SIZE | The size of the buffers in the send/recv queues |
PSP_PORTALS_SENDQ_SIZE | Number of send buffers per communication pair |
PSP_PORTALS_RECVQ_SIZE | Number of receive buffers per communication pair |
Rendezvous Communication
As mentioned above, the pscom4portals Plugin implements a Put-based protocol for rendezvous communication. The control logic synchronising the sender and the receiver is already provided by the hardware-independent part of the pscom. The pscom4portals has to provide callbacks for the registration and de-registration of memory regions as well as for issuing the actual PUT operation.
The psptl layer of the pscom4portals plugin supports the fragmentation of a single rendezvous message into smaller chunks to support message transfers exceeding limitations imposed by the network hardware. Although this fragmentation defaults to the hardware limit, further performance tuning is possible by setting the according environment variable.
To avoid mismatches of multiple rendezvous transfers between the same pair of processes, the pscom4portals plugin leverages the matching capabilities provided by Portals 4. Therefore, each rendezvous transfer has a unique identifier being used in the match_bits field of the Matching List Entry (ME). This way, multiple rendezvous transfers can be processed concurrently without interfering each other.
Evaluation
Two hardware testbeds were used for the preliminary evaluation of the BXI support in ParaStation MPI: (1) the Dibona system and (2) the DEEP system. This approach enables the assessment of the functionality and performance on two very different platforms. While the Dibona system is based on the ARM architecture, the DEEP system is a supercomputing system built by following the MSA approach. Further details of both systems can be found in Table 3.
| Dibona | DEEP System | |
|---|---|---|
| Architecture | TSMC ThunderX2 99xx ARMv8.1 | Intel(R) Xeon(R) Gold 5122 |
| Node Count | 12 | 4 |
| Socket Count | 2 | 1 |
| Memory per Node | 48 GiB | 48 GiB |
| Interconnect | BXI 1.3 | BXI 1.3 |
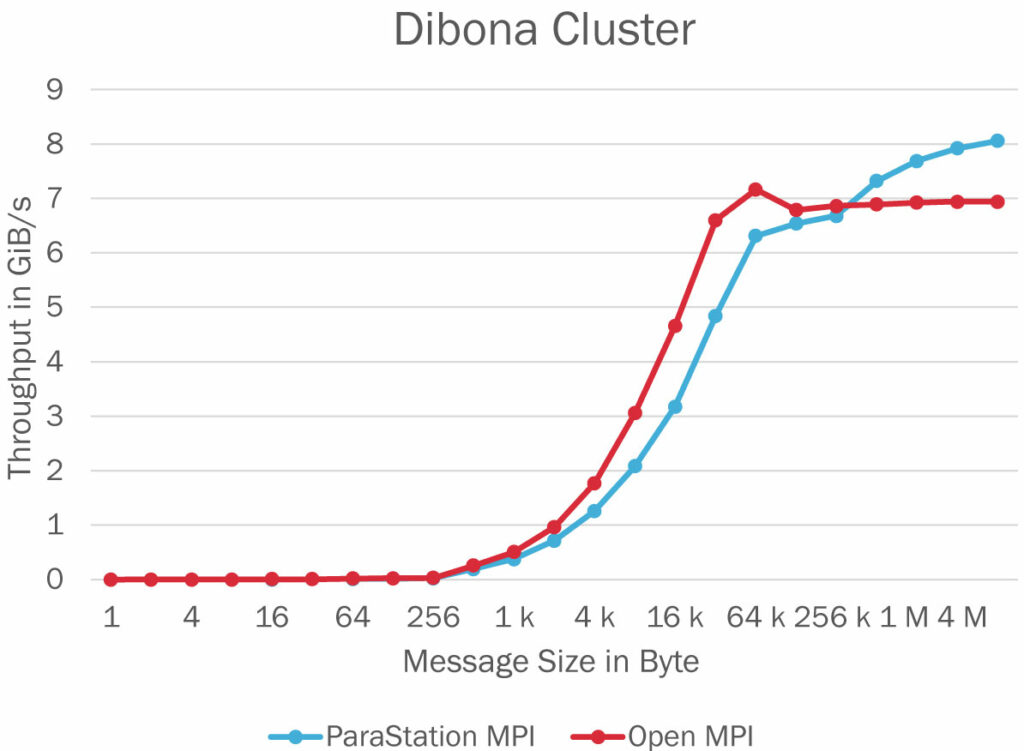
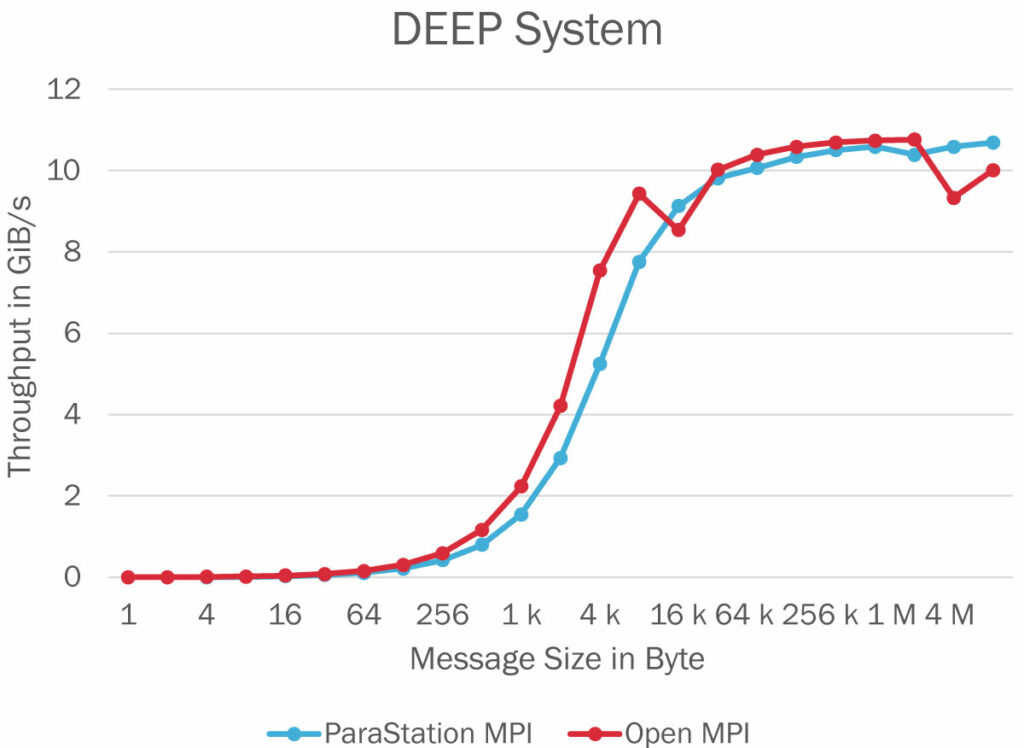
Figures 4 and 5 present the communication throughput obtained with both ParaStation MPI and Open MPI on the Dibona cluster and the DEEP system, respectively.
The numbers have been obtained by running the OSU bandwidth test in the default configuration. ParaStation MPI is reaching a throughput for large size messages that is comparable to the throughput obtained with Open MPI. This leads to the conclusion that the implemented rendezvous protocol based on RMA write operations already yields a decent performance. However, there is still a small performance gap for small to midsize messages. A reason might be the way how MEs are handled on the psptl layer. Currently, there is one ME per communication buffer, negatively impacting the management overhead on the hardware level. This could be circumvented by managing multiple eager buffers within a single ME.
Conclusion
In this blog article, we presented our initial implementation of the pscom4portals plugin enabling efficient MPI communication over BXI networks using the ParaStation MPI communication stack. We could show that this already reaches decent performance for larger messages by relying on a Put-based rendezvous protocol. Currently, we focus on improving the communication latency by optimising the management of the pre-allocated eager buffers and their corresponding MEs. Additionally, we plan to evaluate the communication performance in modular setups exhibiting a heterogeneous network landscape. Therefore, the gateway capabilites provided by ParaStation MPI will enable the bridging between BXI and the InfiniBand network within the DEEP system.
References
[1]: Damian Alvarez. “JUWELS Cluster and Booster: Exascale Pathfinder with Modular Supercomputing Architecture at Juelich Supercomputing Centre”. In: Journal of large-scale research facilities 7 (2021), A183. DOI: 10.17815/jlsrf-7-183.
[2]: William Gropp. “MPICH2: a new start for MPI implementations”. In: Recent Advances in Parallel Virtual Machine and Message Passing Interface. Vol. 2474. 2002, p. 7.
[3]: Simon Pickartz et al. “Non-Intrusive Migration of MPI Processes in OS-bypass Networks”. In: IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). 2016.
[4]: Simon Pickartz. “Virtualization as an enabler for dynamic resource allocation in HPC”. PhD thesis. 2019. DOI: 10.18154/RWTH-2019-02208.
[5]: Infiniband Architecture Specification. Tech. rep. InfiniBand Trade Association, Nov. 2016.
[6]: M. Nüssle et al. “An FPGA-based custom high performance interconnection network”. In: 2009 International Conference on Reconfigurable Computing and FPGAs. Dec. 2009, pp. 113–118. DOI: 10.1109/ReConFig.2009.23.
[7]: M. S. Birrittella et al. “Intel Omni-path architecture: Enabling scalable, high per- formance fabrics”. In: 2015 IEEE 23rd Annual Symposium on High-Performance Interconnects. Aug. 2015, pp. 1–9. DOI: 10.1109/HOTI.2015.22.
[8]: Estela Suarez et al. Modular Supercomputing Architecture – A success story of European R&D. Tech. rep. ETP4HPC, May 2022.
[9]: Ronald Brightwell et al. “The Portals 4.3 Network Programming Interface”. In: (June 2022). DOI: 10.2172/1875218. URL: https://www.osti.gov/biblio/1875218.