

Authors: Gilles Moreau (CEA), Hugo Taboada (CEA), Marc Pérache (CEA)
1 Introduction
Context
Nowadays, HPC applications scale to several hundred nodes, and MPI has become the de facto standard for internode communication. It abstracts Point-to-Point (P2P) communication to the application developer while taking advantage of the underlying network. With ever increasing demand for bandwidth-oriented communications, new architectures have arisen featuring multiple Network Interface Cards (NICs). To support this and increase potential bandwidth, MPI implementations have thus developed a feature commonly called multirail.
Multirail over multiple NICs englobes two kinds of use cases: first, data striping that is to split one message and distribute fragments among the NICs, second multiplexing that is to dynamically schedule messages on the NICs. In this article, we will expose the development that were made in the MPC framework, CEA’s MPI implementation [4], to support the first use case, data striping. More particularly, we will focus on the data striping (or fragmentation) protocol for BXI networks [1].
As said earlier, nowadays applications require fast compute and fast network to simulate more and more complex phenomenon and they do so by distributing computation onto hundreds of nodes thanks to communication middlewares implementing the MPI standard. One of the major bottlenecks of such middlewares are copies. We will focus here on two kind of copies that come from the fact that to send user data from one machine to the other, intermediate copies may be needed: first, some are inherent from the underlying protocol (TCP/IP for example) and second others are due to the asynchronicity of MPI communications. The former can be illustrated when an MPI_Send call is performed by the sender before and MPI_Recv has been posted by the receiver. In order not to block the sender from doing actual computation, the communication will be done asynchronously, and data will be received and stored on the receiver to an internal buffer until its application buffer is available.
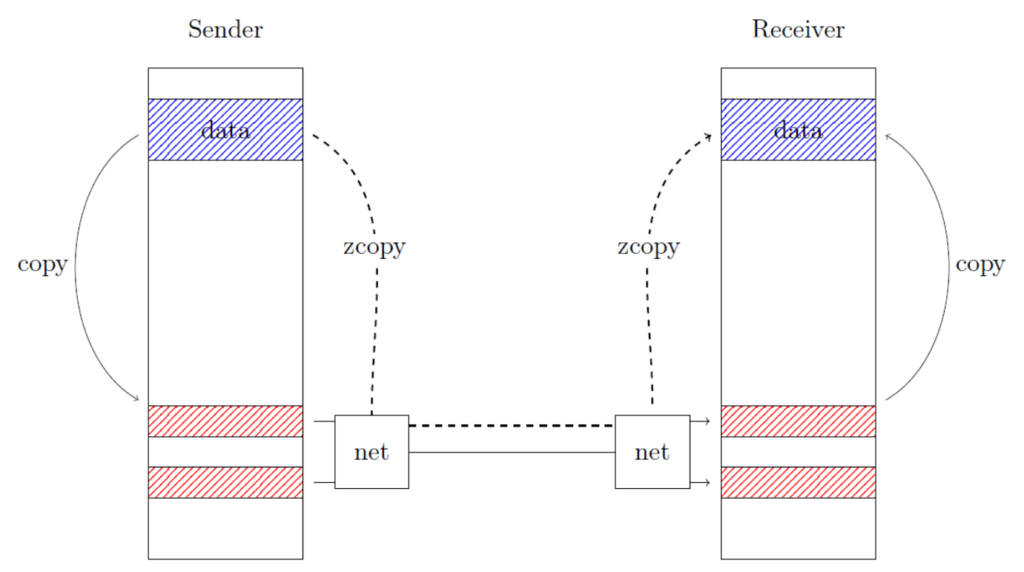
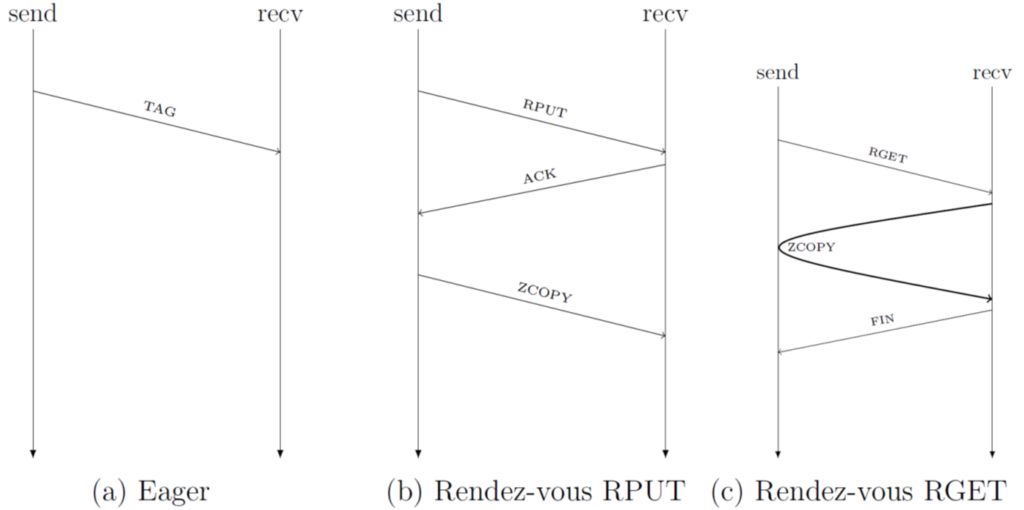
To avoid the first kind of copies, smart-NICs were devised that are capable of doing zero-copy communications. In other words, they are able to read from the send buffer, send it through the network and write it straight to the receive buffer as illustrated in Figure 1, the technology is also called Remote Direct Memory Access (RDMA) [3]. To avoid the second kind, and in the context of two-sided communications (1), actual data transfer must be preceded by a synchronization to prepare the memory that will be targeted and exchange information mandatory for the transfer. Such synchronization is performed through rendez-vous protocols that can be of different types, see Figure 2. While this would be suited for bandwidth-oriented communication, message can also be sent eargerly to improve latency at the cost of copies. It is then the role of the implementation to choose which protocol is best, based on the underlying network and other metrics. [6] gives an interesting overview of the different protocols.
Note 1: We refer the reader to the MPI standard for more information on one- sided and two-sided communications, https://www.mpi-forum.org/docs/mpi-4.0/ mpi40-report.pdf
Problematic
MPC’s architecture can be represented by two layers. The first layer implements all MPI-related constraints specified by the standard such as tag-matching, communicators, or message ordering. The second layer (rail layer) exposes an API that implements P2P communications over the different type of networks such as TCP/IP, InfiniBand or BXI. One major implementation design is that protocols described earlier are implemented transparently by the rail layer. As a consequence, using such API to implement the data striping protocol could imply a synchronization for all fragments, thus inducing an important performance penalty. Indeed, only one rendez-vous would be necessary to implement this protocol and prepare the memories.
Therefore, we present in this article how we modified MPC’s architecture to avoid such overhead with the introduction of a protocol layer called LowComm Protocol (LCP). Mostly, we motivate its developments without going into its complete implementation. We will first describe its design principles (active message paradigm) that guided the development, we will then explain why we completed it with a new data path to adapt for BXI networks. Finally, we will present preliminary results that validate the multirail.
2 Contributions
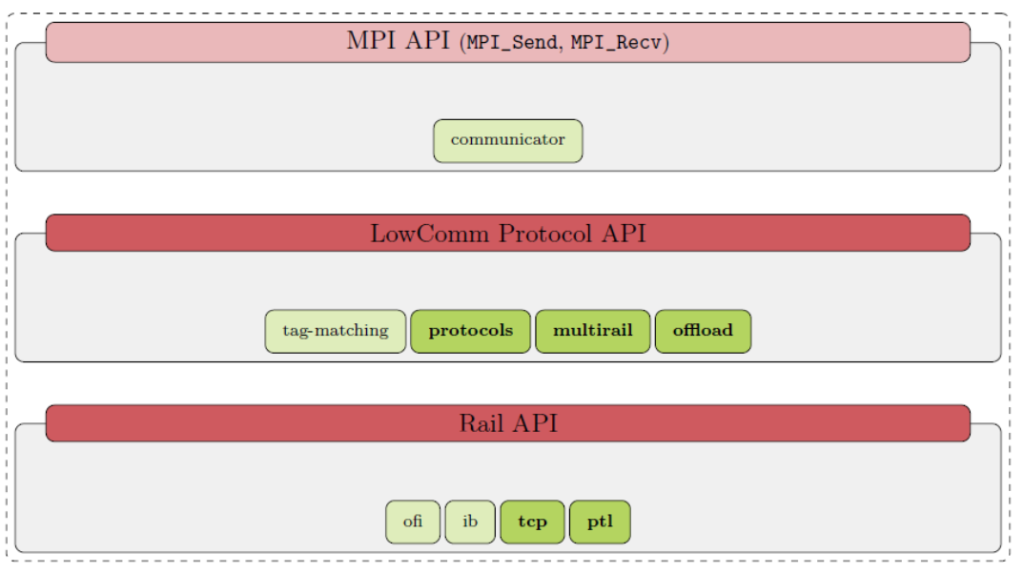
This section describes how we implemented the protocol layer in MPC based on the active message paradigm. More particularly, we describe four contributions represented in Figure 3: protocol development through active messages, the protocol endpoint for multirail, and finally our optimization for BXI networks.
Protocol development
Active messages are an asynchronous communication mechanism in which each message contains in its header the address of a user-level handler executed on message arrival and with the message body as argument [2]. The handler must execute quickly and to completion. Actually, more than a new communication paradigm, it has been used here as a framework for the development of protocols. In the following description, we will show how this took part in the design of the API.
As said earlier, the current rail API could not be used “as is” for the implementation of the fragmentation protocol, therefore it was necessary to extend it with new calls to avoid the protocol redundancy presented. The goal of the new API is two-fold: first, loosen the function signature to encapsulate useful protocol data in the header, second, essentialize the function semantic to sending bytes of data. The API is shown in the code below and we describe new the Active Message (AM) API.
/** Previous API **/
void send_msg(ptp_msg_t *msg, transp_ep *ep);
/** New Active Message API **/
int send_am(transp_ep *ep, int am_id, void *hdr, int hdr_length, void *buf);
/** New Tag API **/
int send_tag(transp_ep *ep, uint64_t tag, uint64_t imm, void *buf);
int recv_tag(struct rail *rail, uint64_t tag, uint64_t ign_tag, void *buf, struct tag_ctx *ctx); First, we added the active message identifier (int am_id) to the function signature. Upon reception, the corresponding user handler will be called with the message body. Before, ptp_msg_t structure contained the header shipped with the actual payload and which was originally designed to only include MPI matching information (communicator, source, tag, …). Any new protocol data necessary for the fragmentation protocol would thus have to be included in this structure thus resulting in header overload. These constraints have been released by allowing to specify an arbitrary header (void *hdr, int hdr_length) associated with the application buffer (void *buf). Last function argument, we specify that the transport endpoint (transp_ep) contains the connection information for the underlying network (file descriptor for TCP, Queue Pair for InfiniBand, ID for Portals,…). In the RED-SEA project, these calls were implemented only for TCP and BXI transports, support for InfiniBand will be future work. Finally, we added a tag API used for tag-matching interface for which we give more details later on.
The description of the multirail feature can be divided in two parts: first, the container, or support for multi-NICs, and second the controller that is responsible for the fragmentation protocol. The container has been implemented in a new object called protocol endpoint, that contains as many transport endpoints as there are available transports. Most importantly, the protocol endpoint is used to give a coherent configuration in case transport endpoints have heterogenous configurations. For example, not all transports may support the RGET protocol.
The controller is responsible for the progression of the fragmentation protocol as well as other protocols and has been developed in the LowComm Protocol (LCP) layer. It basically relies on a progression engine and a state machine. The progress engine is regularly called and loops over all pending requests, depending on their state the corresponding step of the protocol is performed. This design results from the active message paradigm where handler should run quickly and to completion to avoid deadlock. For example, no large data should be sent in a blocking fashion by the handler. In our first implementation of the fragmentation protocol, the sender initiates a RPUT message to the receiver for synchronization and once the ACK message is received, fragments are sent in a round-robin fashion among the available transport endpoints.
We now explain the development needed for the exploitation of tag- matching interface such as BXI NICs.
Application to BXI networks
One particularity of BXI NICs is that they possess specialized hardware to perform tag-matching. Indeed, for some applications tag-matching could become a bottleneck and offloading this operation to the NICs could results in important performance gains. They also provide zero-copy mechanisms, see Section 1, based on tag-matching, that is sent data is directly written to the memory associated with the pre-posted matching memory descriptor.
For other transports such as TCP or InfiniBand implemented in MPC, tag-matching has to be performed by the software with the classical implementation that uses the combination of the Posted Receive Queue (PRQ) and Unexpected Message Queue (UMQ), see [5] for more information. But this becomes unnecessary when using a tag-matching interface since it is done by the hardware. As a consequence, we developed a new data path in the code adapted to offload the matching. The inconvenient is that most handlers and data paths had to be duplicated with minor changes. This has been developed in the LCP layer, see Figure 3. This new datapath ends up using the specialized calls from the Tag API showed in Figure 4. In particular, the receive call possesses a struct tag_ctx that is passed to the tag-matching driver and will be attached to the memory descriptor so that upon matching, we can get it back and access the matching request.
We now show some preliminary results of this multirail implementation.
3 Results
Validation benchmarks have been run on machines provided by the CEA Inti supercomputer, which features multi-NIC nodes with the BXI network. They are composed of bi-socket AMD Milan (2×64cores) with 256GB of RAM, and each node possesses 4×100Gb/s (=4×12,5GB/s) BXI network cards.
For our performance analysis, we ran Pingpong from IMB benchmarks for message sizes ranging from 4B to 4096MB. In the experiment, fragment size has been set to 64MB which is the maximum message size allowed by the Portals 4 library on this network. Figure 5a acts as a Proof of Concept of the multirail feature and a more careful analysis will be performed.
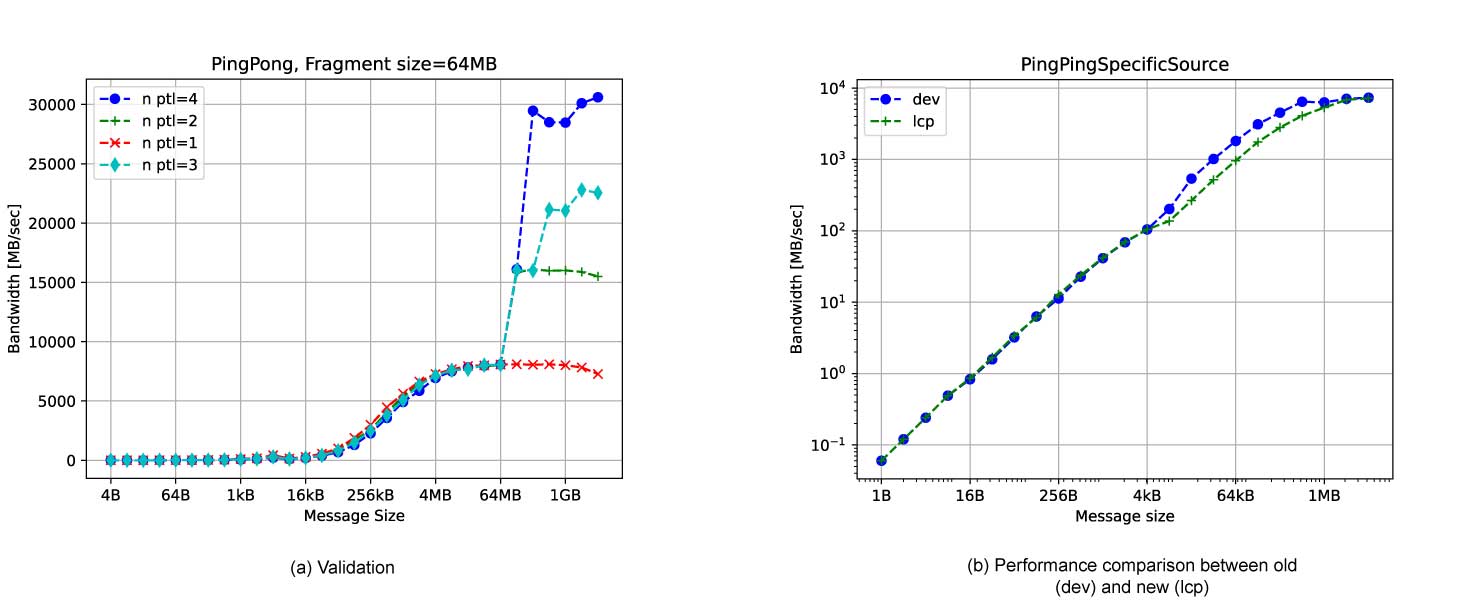
Messages ranging from 4B to 64MB have been showned to better appreciate the outcome of the multirail feature for sufficiently large messages. Additionnally, we show that it introduces a limited overhead. To complete the study on this message range, finer comparisons will have to be undertaken with state of the art MPI implementations, more especially to evaluate the performance of the eager and rendez-vous protocols.
For messages ranging between 64MB to 4GB, the implementation shows coherent results with good scalability. With 4 NICs, bandwidth reached more than 30 000MB/s which make relevant the use of multirail feature in this context. However, a decrease appears for very large messages (≥ 2GB) and for 1 and 2 NICs which may be improved by an optimized use of Portals 4 memory descriptors. For now, each fragment has his own memory descriptor while only one for each NIC would suffice accompanied with offset management. This will be studied for the next deliverable. Moreover, focusing on 256MB message size, one can notice that 3 NICs are as fast as 2 NICs. Indeed, since all fragments are of equal sizes, the message will be split in 4 fragments which will be sent for both configurations in two rounds (2 + 2 for dual-NIC and 3 + 1 for 3-NICs). Data distributions could also be improved in future work.
Figure 5b illustrates how our version compares with the current development version of MPC (2). We show that the LCP layer adds no overhead for messages of size < 8KB which are sent with eager protocol. However, above 8KB we have performance degradation mostly due to the rendez-vous protocol used. While the previous version uses the RGET protocol, we only implemented the RPUT protocol which is less performant.
Note 2: Commit hash: 0f606b8a57afa8b381eda02b1f0176976c9d2356
4 Conclusion
To conclude, we exposed our principal designs for implementing the multirail feature on MPC implementations. We first extended the existing transport API with support for active message paradigm to alleviate some limitations of the current one. We implemented a simplified protocol layer with sufficient handlers for eager and rendez-vous protocols. Finally, we validated the feature with the IMB PingPong benchmark showing decent speedup with an efficiency of more than 85% for large message sizes but the study will have to be completed. In future work, bandwidth for large message sizes should be improved by using RGET protocol whenever possible. Thoughtful code instrumentation will give more insight into the current bottlenecks. Furthermore, implementing this transport API for InfiniBand could be useful.
References
[1] Saïd Derradji et al. “The BXI Interconnect Architecture”. In: 2015 IEEE 23rd Annual Symposium on High-Performance Interconnects. 2015, pp. 18–25. doi: 10.1109/HOTI.2015.15.
[2] Thorsten Von Eicken et al. Active Messages: a Mechanism for Integrated Communication and Computation. 1992.
[3] Jiuxing Liu et al. MPI over InfiniBand: Early Experiences. Tech. rep. 2003.
[4] Marc Pérache, Hervé Jourdren, and Raymond Namyst. “MPC: A Unified Parallel Runtime for Clusters of NUMA Machines”. In: Proceedings of the 14th International Euro-Par Conference on Parallel Processing. Euro- Par ’08. Las Palmas de Gran Canaria, Spain: Springer-Verlag, 2008, pp. 78–88. isbn: 978-3-540-85450-0. doi: 10.1007/978-3-540-85451-7_9. url: http://dx.doi.org/10.1007/978-3-540-85451-7_9.
[5] Whit Schonbein et al. “Measuring Multithreaded Message Matching Misery”. In: Euro-Par 2018: Parallel Processing: 24th International Con- ference on Parallel and Distributed Computing, Turin, Italy, August 27 – 31, 2018, Proceedings. Turin, Italy: Springer-Verlag, 2018, pp. 480–491. isbn: 978-3-319-96982-4. doi: 10.1007/978-3-319-96983-1_34. url: https://doi.org/10.1007/978-3-319-96983-1_34.
[5] Sayantan Sur et al. “RDMA read based rendezvous protocol for MPI over InfiniBand: design alternatives and benefits”. In: In PPoPP ’06: Proceedings of the eleventh ACM SIGPLAN symposium on Principles. 2006, pp. 32–39.