

Salvatore Di Girolamo, ETH Zürich
Need for network acceleration
Datacenter and HPC systems are growing at unprecedented speeds. The Frontier supercomputer has been recently deployed at the Oak Ridge National Laboratory in Oak Ridge, Tenn, making it the first exascale system in the United States. At their core, these systems are a collection of compute nodes communicating via a high-performance interconnection network. For example, the Frontier supercomputer comprises more than 9000 Cray EX nodes, each one equipped with a third-gen AMD Epyc CPU and four Radeon Instinct MI200 GPUs. The compute nodes are connected via the Slingshot 11 interconnect, providing 200 Gbps networking. Frontier will deliver more than 1.5 exaflops of HPC and AI [1]. The interconnection network plays a fundamental role in these systems: as compute jobs run in a distributed fashion, the network must guarantee that compute nodes can communicate efficiently, saving overheads that can otherwise make them spend cycles waiting for communications to complete.
In datacenters, emerging online services such as video communication, streaming, and online collaboration increase the incoming and outgoing traffic volume. Furthermore, the growing deployment of specialized accelerators and general trends towards disaggregation exacerbates the quickly growing network load. To compensate for these ever-growing workloads, interconnection networks are being optimized to achieve higher line rates and lower latencies. For example, the plot below shows the Ethernet speed roadmap (source: Ethernet Alliance) up to 2030. Already today it is possible to achieve 400 GbE, with 800 GbE and 1.6 TbE planned for the next future.
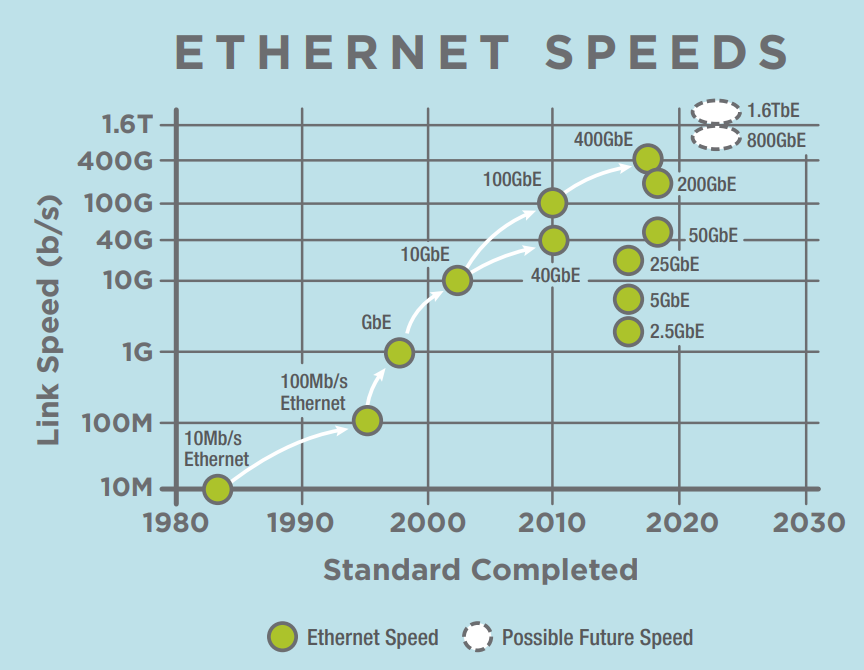
Network speed vs CPU speed
CPU speeds have been historically aligned with networking and storage speeds, making CPUs the natural choice to handle and process incoming network traffic. However, as Moore’s Law comes to an end, this scenario is not viable anymore [2]. The plot below shows trends for storage, network, and DRAM bandwidths. There, it is possible to notice how trends for storage and network bandwidths are starting to dramatically diverge from the DRAM one (the y-axis is log scale), raising a serious call for action. The plot shows DRAM bandwidth instead of cores as it can be seen as a proxy for the bandwidth of the CPU subsystem.
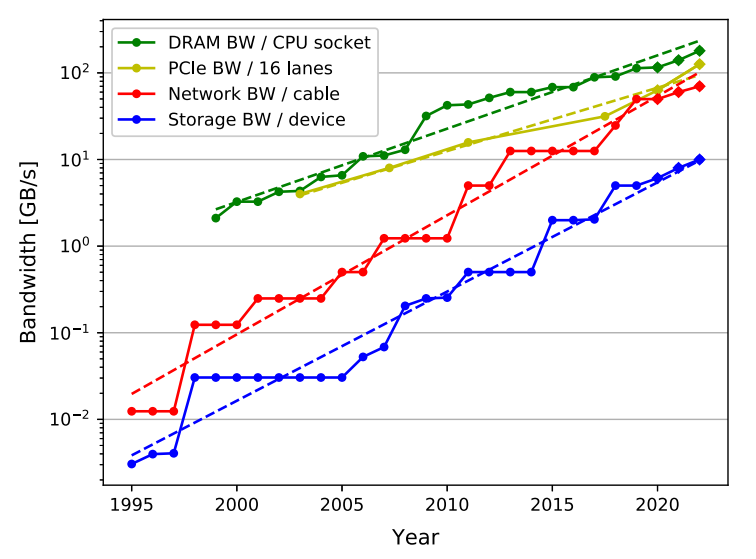
Need of accelerating network communications
To reduce the role of the CPU in the processing of network data, remote direct memory access (RDMA) networks move much of the packet and protocol processing to fixed-function hardware units in the network card and directly access data into user-space memory. With RDMA networks, an initiator process can access the memory of a target process running on a remote node (for reading, writing, or performing atomic memory operations) without involving the CPU and the operating system of the target node. The figure below depicts a communication via standard TCP/IP network stack and via RDMA.
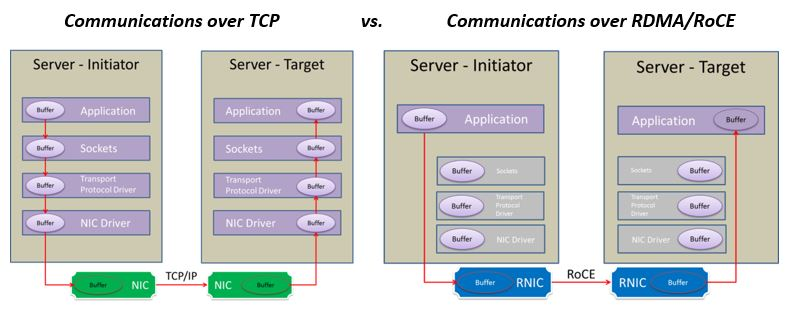
Even though RDMA greatly reduces packet processing overheads on the CPU, the incoming data must still be processed. This means that once the data is delivered into memory, the target CPU that needs to access and process incoming data must move the data through the cache hierarchy and still be able to process it at speed. To free CPU from network data processing tasks, a flurry of specialized technologies exists to move additional parts of this processing into network cards, e.g., FPGAs virtualization support [5], P4 simple rewriting rules [6], or triggered operations [7]. In addition, recently introduced SmartNICs [8, 9, 10] can be programmed to express custom processing of network data directly on the NIC.
Streaming processing in the network (sPIN)
The sPIN programming model goes a step further and fully liberates NIC programming, allowing user-level applications to take advantage of processing data in the network in a streaming fashion. In particular, sPIN aims to extend the success of RDMA and receiver-based matching to simple processing tasks that are dominated by data movement. The sPIN interface allows programmers to specify kernels, similar to CUDA [11] and OpenCL [12], that execute on the NIC. Differently from CUDA and OpenCL, kernels do not offload compute-heavy tasks but data-movement-heavy tasks, specifically, tasks that can be performed on incoming messages and only require limited local state. Such tasks include starting communications with NIC-based collectives, advanced data steering with MPI datatypes, data processing such as network raid, compression, and database filters. Similar to OpenCL, sPIN’s interface is device and vendor-independent and can be implemented on a wide variety of systems.
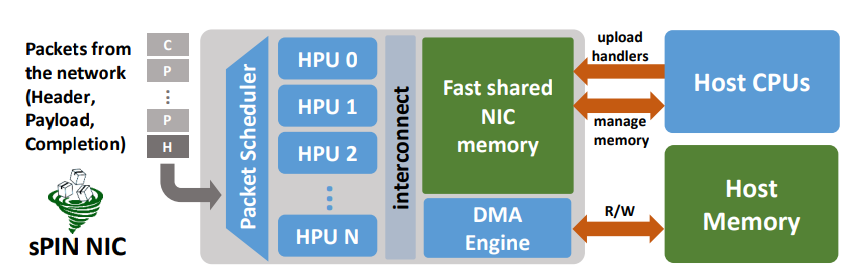
The above figure shows the sPIN abstract machine model. As sPIN is mainly a programming model, it does not define a specific architecture but rather an abstract one that can then be mapped on actual implementations. There, packets coming from the network are deposited into a fast shared NIC memory. For each incoming network packet, an execution task is created by the scheduler and dispatched to one Handler Processing Unit (HPU), where application-defined packet handlers are executed. Handlers can interface the rest of the system via the sPIN API for, e.g., moving data to host memory via PCIe or sending it through the network via the NIC outbound engine. Differently from existing SmartNIC solutions, where long-lived threads poll for new packets (or bursts of packets) coming from the network, sPIN handlers are defined to operate on a single packet. On one side, this eases programmability because the programmer can express directly the task to perform on the network data, without caring about non-functional tasks like efficient polling. On the other side, it allows having multiple packet handlers, expressed by the same or different applications, running on the NIC while still providing features like isolation and fairness.
Packet matching
The sPIN programming model leverages receiver-side matching. Application-defined packet handlers are not executed on all incoming packets (as this would break isolation between applications of the same or different tenants) but only packets belonging to a message (e.g., MPI message) or packet flow (e.g., TCP connection, UDP socket) that is identified by the application offloading the handlers. In particular, an application that wants to use sPIN, defines one or more execution contexts. Each execution context contains a reference to the sPIN handlers to execute, a pointer to pre-allocated NIC memory that will be used by the handlers to share state, and a pointer to a memory buffer in host memory belonging to the application. At this point, the application associates the execution context to a network-specific descriptor, making the sPIN NIC ready to process packets. The table below lists the possible points of integration for existing network technologies.
| Network | Interface | Handlers Descriptor |
| InfiniBand, RoCE | Ibverbs | Queue Pair |
| Bull BXI, Cray Slingshot | Portals 4 | Match List Entry |
| Cray Gemini, Cray Aries | uGNI, DMAPP | Memory Handle |
| Ethernet | Sockets | Sockets |
Designing a sPIN-enabled accelerator
At SPCL, together with the PULP team, we designed an open-source sPIN accelerator, PsPIN [19], that implements the sPIN programming model. PsPIN is built on top of the PULP (Parallel-Ultra-Low Power) platform [14]. HPUs are implemented as RISC-V cores and organized in clusters [15]. Each cluster provides 8 HPUs, a 1 MiB single-cycle access scratchpad, and a DMA engine. While PsPIN can be configured with different numbers of clusters, we use 4 clusters, for a total of 32 HPUs, as in the configuration adopted in the original work. Clusters are interconnected and share a bigger L2 scratchpad (4 MiB), a packet buffer (4 MiB), and program memory (32 KiB). The synthesized PsPIN accelerator (22 nm FDSOI) is clocked at 1 GHz, occupies an area of 18.5 mm^2, and has a maximum power consumption of 6 W. The picture below shows a high-level view of the PsPIN architecture and how it can be integrated into a NIC.
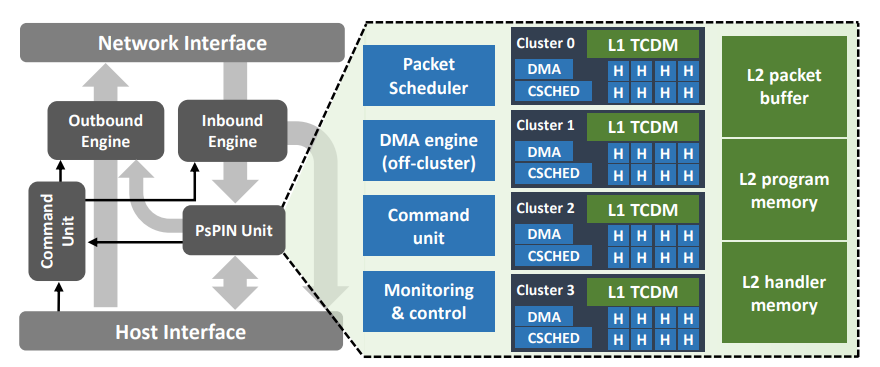
PsPIN is released under SolderPad (for the hardware components) and Apache 2.0 (for the software) licenses and is available on GitHub: https://github.com/spcl/pspin.
Testing your own sPIN packet handlers
Below you can find an example of a ping-pong sPIN handler. This handler, for every packet on which it is executed, swaps IP source and destination addresses and UDP source and destination ports, finally sending it back over the network. There is no need to check if the packet is specifically a UDP packet or if it is a ping packet because the application will install this handler on a UDP socket over which it wants to perform the ping-pong, saving overhead cycles that would be needed to perform these checks on the NIC cores otherwise.
__handler__ void pingpong_ph(handler_args_t *args)
{
task_t* task = args->task;
ip_hdr_t *ip_hdr = (ip_hdr_t*) (task->pkt_mem);
uint8_t *nic_pld_addr = ((uint8_t*) (task->pkt_mem));
uint16_t pkt_pld_len = ip_hdr->length;
udp_hdr_t *udp_hdr = (udp_hdr_t*) (((uint8_t*) (task->pkt_mem)) + ip_hdr->ihl * 4);
uint32_t src_id = ip_hdr->source_id;
ip_hdr->source_id = ip_hdr->dest_id;
ip_hdr->dest_id = src_id;
uint16_t src_port = udp_hdr->src_port;
udp_hdr->src_port = udp_hdr->dst_port;
udp_hdr->dst_port = src_port;
spin_cmd_t put;
spin_send_packet(nic_pld_addr, pkt_pld_len, &put);
}
Together with PsPIN, we provide a testbench to compile and run your own handlers in cycle-accurate simulations. Check https://spcl.github.io/pspin/ for more information.
Use cases for sPIN
To show the importance of application-defined packet processing on the NIC, we showcase two use cases that can benefit from sPIN: non-contiguous memory transfers and distributed file systems.
Network-Accelerated Non-Contiguous Memory Transfers
In a distributed graph traversal such as BFS, the algorithm sends data to all vertices that are neighbors of vertices in the current frontier on remote nodes—here both the source and the target data elements are scattered at different locations in memory depending on the graph structure. More regular applications, such as stencil computations in regular grids used in many PDE/ODE solvers communicate strided data at the boundaries. In applications, such as parallel Fast Fourier Transform, the network can even be used to transpose the matrix on the fly, without additional copies. Such non-contiguous data accesses can account for up to 90% of application communication overheads [16, 17] and optimizations can lead to speedups of up to 3.8x in practice [18].
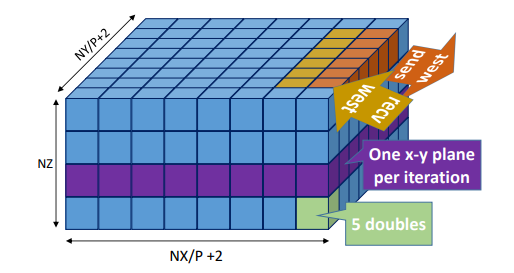
The figure above shows the example of NAS LU that uses a four-dimensional array as main data structure. This is split along two dimensions (x,y) onto a 2D processor grid. The first dimension contains 5 double-precision floats. Each (x,y)-plane corresponds to one iteration of the RHS-solver kernel. In each communication step, neighboring faces (i.e., nx × ny × 10 elements) of the four-dimensional array are exchanged among processors.
In [20], we focus on MPI datatypes, as they enable applications to express arbitrary non-contiguous memory transfers. We demonstrate up to 10x speedup in the unpack throughput of real applications, demonstrating that non-contiguous memory transfers are a first-class candidate for network acceleration. This work shows the benefits of application-defined packet processing as those results can be achieved without the need of a system or firmware update but just via software libraries employed by the application or by the MPI library itself.
Distributed file systems
RDMA-based Distributed File Systems (DFS) is another use case that can benefit from packet processing in the NIC. In these DFSs the CPU of the storage node is bypassed in order to avoid software overheads and additional data copies. Client-side libraries of these DFS can access the memory of the storage nodes directly via RDMA. The main motivation behind RDMA-based DFSs is the advent of fast non-volatile main memories (NVMMs), such as Intel Optane that have performance characteristics similar to DRAM. As without NVMM the bottleneck has always been the storage media, there has been no need to optimize the data path from clients to storage nodes. However, with NVMMs, this is not true anymore, requiring this data path to be optimized.
As RDMA is meant for accelerating data movement, implementing tasks typical of DFSs in RDMA-only systems becomes challenging. Examples of these tasks are data replication, erasure coding, and client authentication. With sPIN, such tasks can be expressed as packet handlers to be executed on the NIC of the storage nodes, directly on the data path. Preliminary benchmarks executed within the PsPIN test benches described above show latency improvements for non-resilient writes (up to 2x), replicated writes (up to 4x), and erasure-coded writes (up to 3x), with respect to comparable non-offloaded versions.
Next steps
The research activity around the sPIN project goes in three directions: programming model, architecture, and use cases. From the architecture perspective, we are looking into simpler architectures (e.g., Snitch) for the next generation of PsPIN. By having a simpler architecture, we will be able to improve both area and power efficiency and re-invest those savings for more on-NIC cores (i.e., to exploit the embarrassingly parallel nature of packet processing) and workload-specific hardware accelerator (e.g., crypto). Additionally, we are exploring how well this programming model applies to network switches as well. In the FLARE [21] paper, we explore in-switch allreduce operations into the network, showing how a sPIN-based approach to in-switch compute not only provides a 2x speedup over non-offloaded allreduce operations but provide high flexibility by not requiring to set up the reduction tree in advance and by enabling users to use custom operators and reduction schemes (e.g., for sparse reductions).
Demo
Additional resources
 | sPIN: High-Performance Streaming Processing in the Network https://www.youtube.com/watch?v=eSz23-EFg2o |
 | New trends for sPIN-based in-network computing – from sparse reductions to RISC-V https://www.youtube.com/watch?v=Jfn8LusAR1I |
 | A RISC-V in-network accelerator for flexible high-performance low-power packet processing https://www.youtube.com/watch?v=7W-o0FCCGQY |
 | Network-accelerated non-contiguous memory transfers https://www.youtube.com/watch?v=T3kwYadi3k0 |
 | Flare: Flexible In-Network Allreduce https://www.youtube.com/watch?v=gGPmnI-cJvE |
Note of the author
The content of this blog post is mainly based on the following publications:
- Hoefler, Torsten, Salvatore Di Girolamo, Konstantin Taranov, Ryan E. Grant, and Ron Brightwell. “sPIN: High-performance streaming Processing in the Network.” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1-16. 2017.
- Di Girolamo, Salvatore, Andreas Kurth, Alexandru Calotoiu, Thomas Benz, Timo Schneider, Jakub Beránek, Luca Benini, and Torsten Hoefler. “A RISC-V in-network accelerator for flexible high-performance low-power packet processing.” In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pp. 958-971. IEEE, 2021.
- Di Girolamo, Salvatore, Konstantin Taranov, Andreas Kurth, Michael Schaffner, Timo Schneider, Jakub Beránek, Maciej Besta, Luca Benini, Duncan Roweth, and Torsten Hoefler. “Network-accelerated non-contiguous memory transfers.” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1-14. 2019.
References
[1] https://www.hpcwire.com/2021/09/29/us-closes-in-on-exascale-frontier-installation-is-underway/
[2] https://blog.westerndigital.com/cpu-bandwidth-the-worrisome-2020-trend/
[3] https://link.springer.com/article/10.1007/s00778-019-00581-w
[4] Doubling Network File System Performance with RDMA-Enabled Networking | NVIDIA Developer Blog.
[5] Firestone, Daniel, Andrew Putnam, Sambhrama Mundkur, Derek Chiou, Alireza Dabagh, Mike Andrewartha, Hari Angepat et al. “Azure accelerated networking: Smartnics in the public cloud.” In 15th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 18), pp. 51-66. 2018.
[6] Bosshart, Pat, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger et al. “P4: Programming protocol-independent packet processors.” ACM SIGCOMM Computer Communication Review 44, no. 3 (2014): 87-95.
[7] Barrett, Brian, Ronald B. Brightwell, Ryan Grant, Kevin Pedretti, Kyle Wheeler, Keith D. Underwood, Rolf Riesen, Arthur B. Maccabe, Trammel Hudson, and Scott Hemmert. The Portals 4.1 network programming interface. No. SAND2017-3825. Sandia National Lab.(SNL-NM), Albuquerque, NM (United States), 2017.
[8] https://www.nvidia.com/en-us/networking/products/data-processing-unit/
[9] https://www.broadcom.com/products/ethernet-connectivity/smartnic
[10] https://www.netronome.com/products/agilio-cx/
[11] Nickolls, John, Ian Buck, Michael Garland, and Kevin Skadron. “Scalable parallel programming with cuda: Is cuda the parallel programming model that application developers have been waiting for?.” Queue 6, no. 2 (2008): 40-53.
[12] Stone, John E., David Gohara, and Guochun Shi. “OpenCL: A parallel programming standard for heterogeneous computing systems.” Computing in science & engineering 12, no. 3 (2010): 66.
[13] Hoefler, Torsten, Salvatore Di Girolamo, Konstantin Taranov, Ryan E. Grant, and Ron Brightwell. “sPIN: High-performance streaming Processing in the Network.” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1-16. 2017.
[14] Rossi, Davide, Francesco Conti, Andrea Marongiu, Antonio Pullini, Igor Loi, Michael Gautschi, Giuseppe Tagliavini, Alessandro Capotondi, Philippe Flatresse, and Luca Benini. “PULP: A parallel ultra low power platform for next generation IoT applications.” In 2015 IEEE Hot Chips 27 Symposium (HCS), pp. 1-39. IEEE, 2015.
[15] Kurth, Andreas, Pirmin Vogel, Alessandro Capotondi, Andrea Marongiu, and Luca Benini. “HERO: Heterogeneous embedded research platform for exploring RISC-V manycore accelerators on FPGA.” arXiv preprint arXiv:1712.06497 (2017).
[16] Schneider, Timo, Robert Gerstenberger, and Torsten Hoefler. “Application-oriented ping-pong benchmarking: how to assess the real communication overheads.” Computing 96, no. 4 (2014): 279-292.
[17] Schneider, Timo, Robert Gerstenberger, and Torsten Hoefler. “Application-oriented ping-pong benchmarking: how to assess the real communication overheads.” Computing 96, no. 4 (2014): 279-292.
[18] Hoefler, Torsten, and Steven Gottlieb. “Parallel zero-copy algorithms for fast fourier transform and conjugate gradient using MPI datatypes.” In European MPI Users’ Group Meeting, pp. 132-141. Springer, Berlin, Heidelberg, 2010.
[19] Di Girolamo, Salvatore, Andreas Kurth, Alexandru Calotoiu, Thomas Benz, Timo Schneider, Jakub Beránek, Luca Benini, and Torsten Hoefler. “A RISC-V in-network accelerator for flexible high-performance low-power packet processing.” In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pp. 958-971. IEEE, 2021.
[20] Di Girolamo, Salvatore, Konstantin Taranov, Andreas Kurth, Michael Schaffner, Timo Schneider, Jakub Beránek, Maciej Besta, Luca Benini, Duncan Roweth, and Torsten Hoefler. “Network-accelerated non-contiguous memory transfers.” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1-14. 2019.
[21] De Sensi, Daniele, Salvatore Di Girolamo, Saleh Ashkboos, Shigang Li, and Torsten Hoefler. “Flare: flexible in-network allreduce.” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1-16. 2021.